- Amazon EMR 是行业领先的云大数据平台,可使用多种开放源代码工具处理大量数据,例如 Apache Spark、Apache Hive、Apache HBase、Apache Flink、Apache Hudi 和 Presto。
- 步骤(Step)是包含一个或多个 Hadoop 作业的工作单元。步骤通常用于传输或处理数据。一个步骤可能会提交工作至集群。其他步骤可能会处理提交的数据,然后将已处理的数据发送至特定位置。
AWS的EMR Service在2019年11月作出了重大改进,可以支持同时执行多个 EMR 步骤(Step Concurrency)了。官方说从EMR 5.28.0版本开始就可以享受这一功能,真是可喜可贺!
由于项目中使用EMR来跑Spark Job的地方还不少,本着能省一些是一些,充分利用资源的原则,我们也与时俱进的升级了EMR版本,期待着从此Step在ERM上起飞~~。。。当然,现实是不会这么顺利的,过程的艰辛就不讲了,这里记录下使用EMR Step Concurrency如何使用,及使用过程中遇到的几个问题及解决方案。
使用Step Concurrency
EMR 5.28.0版本及之后的版本,支持了并行执行步骤和取消正在执行的步骤。要使用这个功能十分简单:
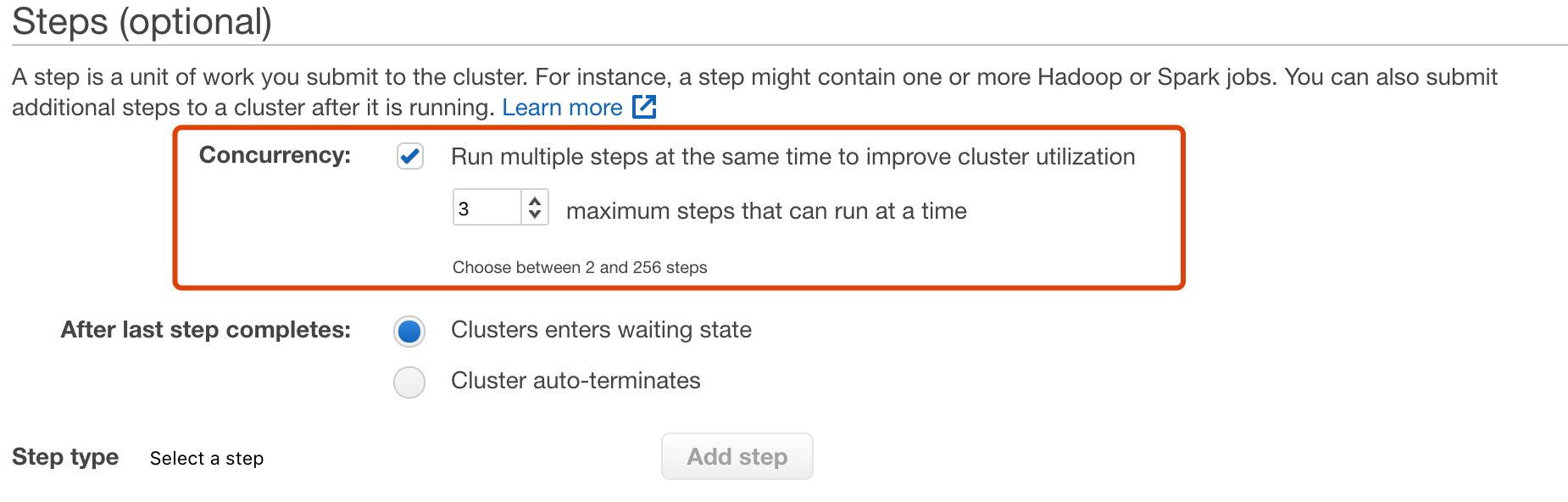
- Console中,在create emr的时,Steps选项中勾选Concurrency,并设置最大的并行度,如下图:
- 如果用的是API,以python的boto3为例,启动EMR时需要传一个StepConcurrencyLevel,类似:
1
2
3
4
5
6
7
cluster_id = client.run_job_flow(
Name=cluster_name,
LogUri=EMR_LOG_DIR,
ReleaseLabel='emr-5.29.0',
Instances={...},
StepConcurrencyLevel=EMR_STEP_CONCURRENCY,
)['JobFlowId']
只要设置了step_concurrency,当在EMR中add了多个step的时候,你会发现这些step同时显示running的状态了:

那么,这些step是不是真正run起来了呢?要是这么简单的话,就不会有这篇文章了好嘛!千万不要被AWS UI上的显示骗了,我们需要更进一步的分析。下面,开始今天的重点,说下如何在EMR上实现真正的step concurrency~
Trouble Shooting
Check Spark History Server
在上面的UI中,我们可以看到有3个并行的step。但是当打开Spark的UI(入口:Application user interfaces -> Spark history server)时,会发现只有两个application:
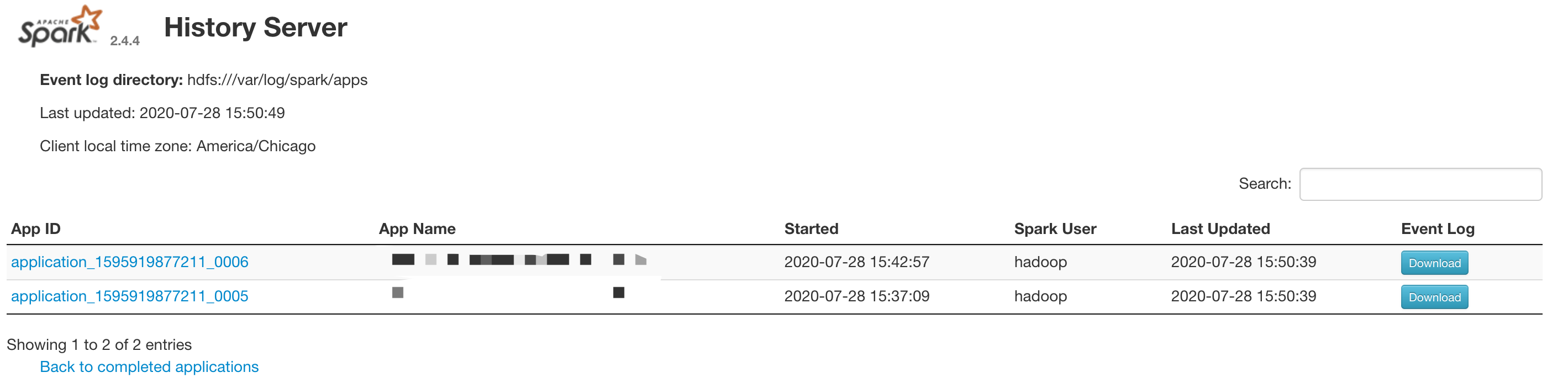
另一个application去哪了呢?这时,只要检查下step的errlog,就会发现类似下面的log Application is added to the scheduler and is not yet activated:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
20/07/28 07:37:22 INFO Client:
client token: N/A
diagnostics: [Tue Jul 28 07:37:21 +0000 2020] Application is added to the scheduler and is not yet activated. Queue's AM resource limit exceeded. Details : AM Partition = CORE; AM Resource Request = <memory:31552, vCores:1>; Queue Resource Limit for AM = <memory:94208, vCores:1>; User AM Resource Limit of the queue = <memory:94208, vCores:1>; Queue AM Resource Usage = <memory:63104, vCores:2>;
ApplicationMaster host: N/A
ApplicationMaster RPC port: -1
queue: default
start time: 1595921841669
final status: UNDEFINED
tracking URL: http://ip-10-205-86-1.ec2.internal:20888/proxy/application_1595919877211_0006/
user: hadoop
20/07/28 07:37:23 INFO Client: Application report for application_1595919877211_0006 (state: ACCEPTED)
20/07/28 07:37:24 INFO Client: Application report for application_1595919877211_0006 (state: ACCEPTED)
20/07/28 07:37:25 INFO Client: Application report for application_1595919877211_0006 (state: ACCEPTED)
20/07/28 07:37:26 INFO Client: Application report for application_1595919877211_0006 (state: ACCEPTED)
翻译一下,就是由于AM(ApplicationMaster)资源不足,application提交给了yarn scheduler但没有被执行。这就是在spark的ui中没有显示第三个spark job的原因。那么,为什么会AM资源不足呢?这个原因就复杂了。
首先,需要了解EMR有3中类型的instances:Master,Core,Task,它们的作用各不相同,详情见Understanding Master, Core, and Task Nodes
- Master: 管理集群,通常运行分布式应用程序的主要组件。如, YARN ResourceManager,HDFS NameNode 等。
- Core: 由主节点 (master node) 进行管理。运行数据节点守护程序以将数据存储作为 Hadoop 分布式文件系统 (HDFS) 的一部分进行协调。它们还运行任务跟踪守护程序,并对安装的应用程序所需的数据执行其他并行计算任务。如,YARN NodeManager daemons、Hadoop MapReduce tasks, and Spark executors 等。AM也运行在Core节点上。
- Task: Task node是可选的。主要用来执行任务,如,Hadoop MapReduce tasks, and Spark executors 等。任务节点不运行数据节点守护程序,也不在 HDFS 中存储数据。
其中,core节点和task节点都可用来执行任务。不同的是,core节点上会存储一些关键信息,所以一般选择的是ondemand的实例。而task节点不在HDFS中存储信息,当节点终止时也不影响整个job的完成,所以通常task节点会选择Spot 实例来节省成本。
回到上面的log,可以看到几个关键信息:
- job请求的AM资源:AM Resource Request = <memory:31552, vCores:1>;
- 分配给AM的资源: Queue Resource Limit for AM = <memory:94208, vCores:1>;
- AM已经使用的资源: Queue AM Resource Usage = <memory:63104, vCores:2>;
计算一下就知道,CORE节点分配给AM的资源只够支持并行两个spark job的。想要支持更多的step并行,有两个方法:
-
提高分给AM的memory:
- 修改CapacityScheduler的参数,调大 yarn.scheduler.capacity.maximum-am-resource-percent (常用的方法,这边直接调到了0.9,简单粗暴~)
Property Description yarn.scheduler.capacity.maximum-am-resource-percent / yarn.scheduler.capacity. .maximum-am-resource-percent 集群中用于运行应用程序ApplicationMaster的资源比例上限,该参数通常用于限制处于活动状态的应用程序数目。该参数类型为浮点型,默认是0.1,表示10%。所有队列的ApplicationMaster资源比例上限可通过参数yarn.scheduler.capacity. maximum-am-resource-percent设置(可看做默认值),而单个队列可通过参数yarn.scheduler.capacity. .maximum-am-resource-percent设置适合自己的值。 - 增加core节点的memory,就是换内存更大instance type,或是多起个core instance。
-
降低spark job的 driver-memory,即 AM Resource Request ,当然前提是降了后不影响job的执行。
调整的最终目的是让AM的能获得的总资源和并行run step需要的资源达到一个平衡的状态。经过第一轮调整,在spark ui中终于能够看到3个并行的application在跑了。
Check Running Applications
在spark ui中能看到并行的application了,是不是就万事大吉了?当然不是。如果一个个点具体的application进去看,会发现有些其实是没有在跑的,如下图:

点开Executors标签看看:
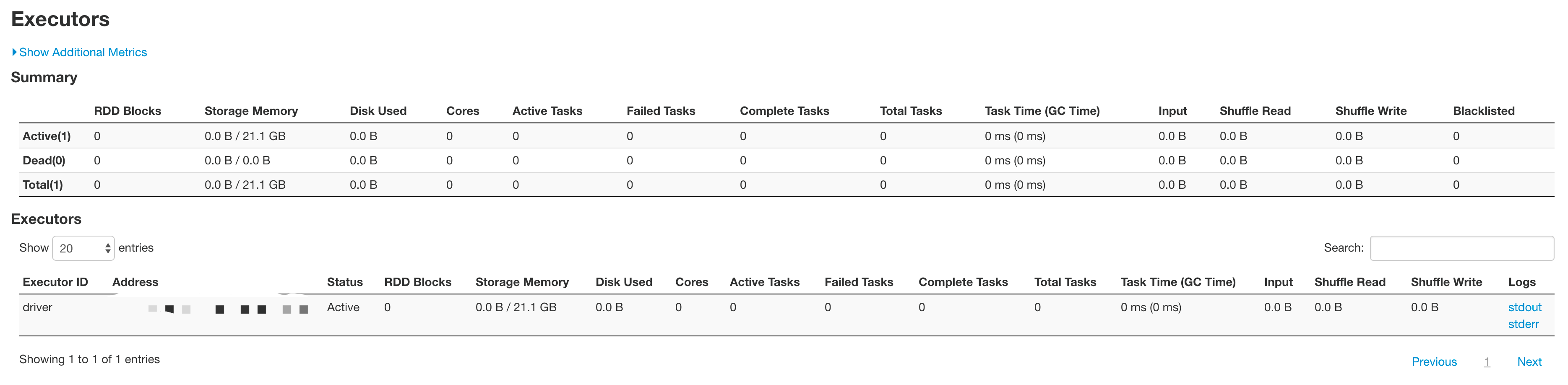
原来,这个application虽然拿到了driver的资源,但并没有分配到执行task需要的executor资源,怪不得跑不起来呢。我们已经知道,spark tasks是在core node和task node上执行的,那么要想让这些application能跑起来,同样有两个方法:
- 增加core node或task node的资源,如vcpu, memory
- 减少spark-submit请求的spark.executor.memory,spark.executor.instances
修改完后,终于所有的application真正并行的run起来了~
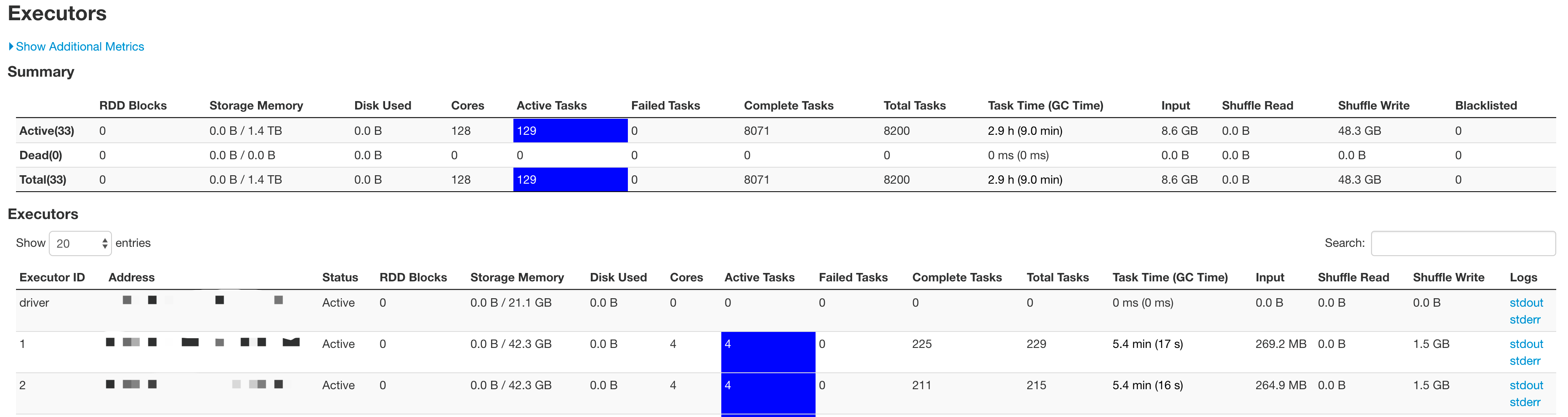
这里需要指出的是,对于单个的spark job来说,由于stage和task划分的关系,可能某些时候executor上并没有active task,这部分executor就处于一个空闲的状态。但是这些空闲的executor并不能被分配给其他的application使用,只有当一个application completed后,它所占用的资源才会被释放给其他application。
如下图,这个application就占用了128个core,但只有2个running的task,其他的126个core处于空闲状态,但也不能用来跑其它application的tasks,是相当的浪费啊。
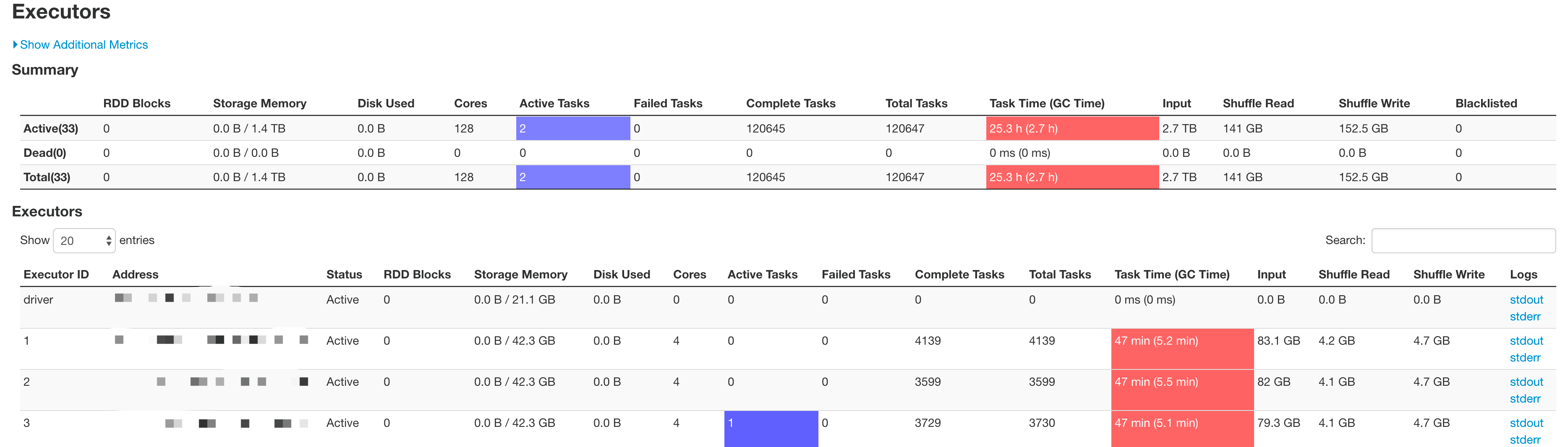
所以,可以理解为step内部的时间资源利用对EMR来说算是个黑盒。EMR只知道每个step请求了多少资源,然后根据当前EMR的资源使用情况把多余的资源分给各个step。至于各个step是不是真正用上了这些资源,它就管不着了。即使用了EMR的step concurrency,也没办法保证EMR的资源的充分利用,还是要继续spark参数调优。
Issue at EMR Startup
最后,介绍一个在EMR启动阶段遇到的小问题。
前面已经提过,EMR中执行具体任务的有core和task两种节点。而在EMR启动过程中,不难观察到task节点总是最后ready的。而一个EMR只要所有的master节点和core节点ready了,它的状态就会由变成waiting,也就意味这可以run step了。
如果通过API来启动EMR并add step的话,一般是观察到EMR返回waiting状态就会认为它启动完成,进而开始add step。但是,由于这个时候的task节点并没有ready,最开始加入的step(也就是spark job)是跑在core节点上的。这样就会占用大量core节点的cpu和memory。
我们已经知道,AM也是跑在core节点上的,上面这种情况的发生就导致了后续加入的spark job会由于AM资源不够而没法被调度。如果看到下面的log,有可能是这个原因:
1
diagnostics: [Thu Jul 16 08:48:46 +0000 2020] Application is Activated, waiting for resources to be assigned for AM. Details : AM Partition = CORE ; Partition Resource = <memory:253952, vCores:32> ; Queue's Absolute capacity = 100.0 % ; Queue's Absolute used capacity = 99.773186 % ; Queue's Absolute max capacity = 100.0 % ;
为了解决这个问题,咨询了AWS support,回复是可以通过修改yarn node labels让CORE节点不执行task,这样就有更多的资源分给AM了:
To overcome this, we can change the Yarn node labels which will enable the CORE nodes to reserve resources for the AM. This will allow more room for AM’s, while the jobs compute containers are launched on TASK nodes [2]. We achieved this by the following commands:
1. Check labels of cluster
$ yarn cluster --list-node-labels
2. Remove CORE label
$ yarn rmadmin -removeFromClusterNodeLabels CORE
3. Add new CORE label with exclusivity set to true
$ yarn rmadmin -addToClusterNodeLabels "CORE(exclusive=true)"
不幸的是,对于使用API启动EMR并执行任务的我们来说,并不能在启动EMR时通过修改conf来达到上面的效果,也不能在EMR的bootstrap脚本中加入上述命令(会报yarn: command not found)。可行的方法是在EMR启动后,通过加入一个step来执行一个shell(changeLabel.sh):
1
2
3
4
#!/bin/bash
yarn rmadmin -removeFromClusterNodeLabels CORE
yarn rmadmin -addToClusterNodeLabels "CORE(exclusive=true)"
yarn cluster --list-node-labels
到此,在EMR上执行step concurrency所遇到的问题终于全部解决了~
后记
作为一个Spark 小白,性能调优这块对我来说一直类似玄学。通过这次对EMR Step concurency问题的排查,阴差阳错的对这块稍微有些入门,当然依然是前路漫漫。
今天的内容就到这了,如果觉得对你有帮助的话,请关注我的微信号,让我们共同成长进步~

本文作者:Jessychen
版权声明:本博客所有文章除特别声明外,均采用CC-BY-NC-SA 4.0 Int'l许可协议
如需转载,烦请注明出处: