Some systems can get overwhelmed when too many processes hit them at the same time. Airflow pools can be used to limit the execution parallelism on arbitrary sets of tasks.
背景
最近,项目中用Airflow重写了某个系统的调度方式。本地各种测试都好好的,而放到线上后,突然收到大量task fail的报警![]() 。查看log发现几个灵异现象:
。查看log发现几个灵异现象:
-
Airflow UI上加载不了log,需要到机器上才能看;
-
显示fail的task,并没有错误或异常,只是进程被kill了,task log显示
INFO - Task exited with return code -9
也就是说,Airflow不知道出于什么原因把正在跑的task给kill掉了。继续查,发现有log<TaskInstance: *** [running]> detected as zombie。看来和zombie 有关。然而,又是什么原因导致大量zombie tasks的产生呢?最后,查找system log,发现是OOM了,python的进程由于OOM被os kill了。
于是,初步估计是DAG并行run的task太多,folk出来的进程太多,使worker撑不住了。为了验证这个猜想,加了一台worker后再跑,果然不再报错了👍。看来并行的task多了,对airflow本身的schedule也是个不小的考验。
只是,加worker的方式总归是个临时的补救方案,那么有没有更好的办法,能对tasks的并发做一个限制,减轻worker的压力,不影响其他dag的tasks呢?调研后发现,Airflow中的pool能实现这个需求。
实现
用Pool来限制tasks的并发相当简单,只需要几步操作。
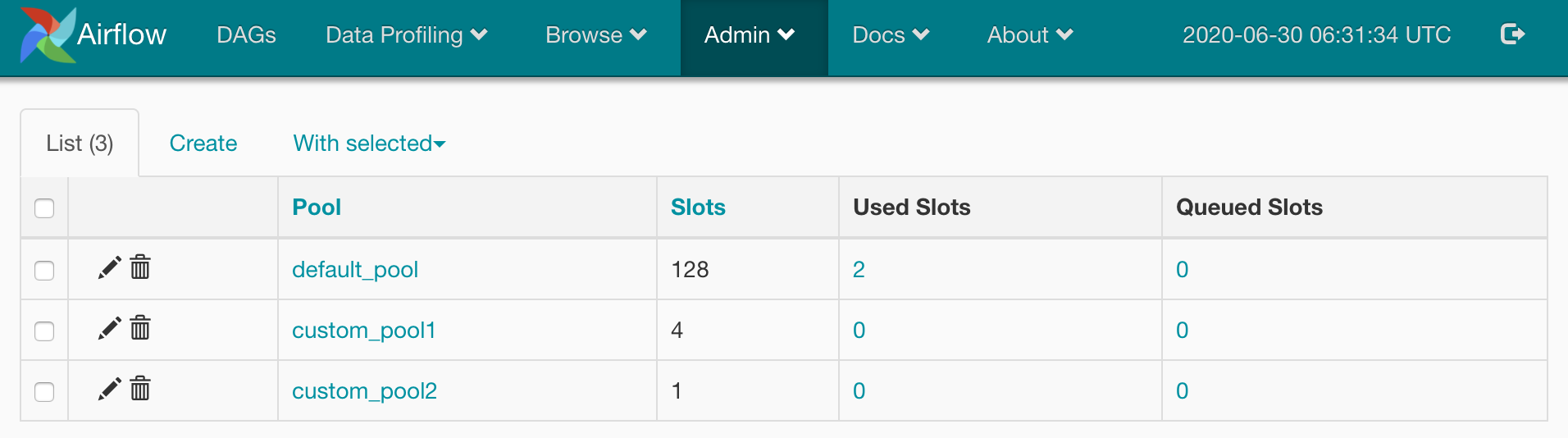
1. 在Airflow UI 上建custom pool。
Pool的UI入口在: Admin->Pools。
UI上可以看到,设置前,整个Airflow只有一个default pool,Slots=128个。这里Slot的意思可以理解为这个pool里可以同时跑128个tasks。
点击create,建立需要的custom pool,设置slot数。下面分别建了custom_pool1和custom_pool2两个pool,slots设为4和1。
2. 修改DAG code
有了自定义的pool后,要做的就是在code里指定我们要的pool:
1
2
3
4
5
6
7
8
9
10
11
12
pool_op1 = PythonOperator(
task_id = "cus_pool_1",
python_callable = cus_pool1,
pool = "custom_pool1", #this line is to identify the pool
dag = dag
)
pool_op2 = PythonOperator(
task_id = "cus_pool_2",
python_callable = cus_pool2,
pool = "custom_pool2", #this line is to identify the pool
dag = dag
)
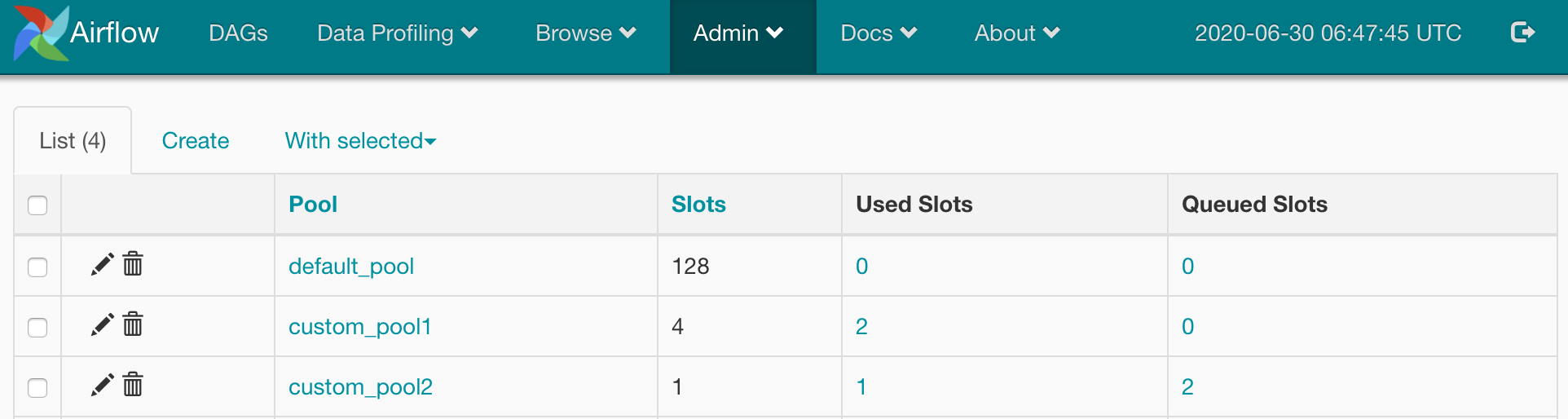
3. Check
最后,trigger对应的DAG,可以看到指定了对应custom pool的task消耗的是custom pool中的slots。在并行task数目大于可用slots的情况下,task会进行排队。
源码
Airflow是怎么实现pool机制的呢?这里来看下它的源码吧。
Pool Struct
Pool的结构定义在airflow.models.pool,git地址:https://github.com/apache/airflow/blob/master/airflow/models/pool.py
- class PoolStats,比较好理解是统计pool的使用情况,有3个统计项,分别对应slots总数,正在running的数目,queued的数目,和UI上面显示相对应。
1
2
3
4
5
class PoolStats(TypedDict):
""" Dictionary containing Pool Stats """
total: int
running: int
queued: int
-
class Pool,定义了一些Pool的基本操作。可以看到pool的信息都是存在DB中
slot_pool这张表里的。class中的pool对应的是pool_name,slots对应pool中的slot总数,可以设为-1,表示这个pool不限制并行的任务(当然不推荐这么做)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
class Pool(Base):
"""
the class to get Pool info.
"""
__tablename__ = "slot_pool"
id = Column(Integer, primary_key=True)
pool = Column(String(256), unique=True)
# -1 for infinite
slots = Column(Integer, default=0)
description = Column(Text)
DEFAULT_POOL_NAME = 'default_pool'
-
Class Pool中有3个staticmethod,都是DB query的操作。
前两个
get_pool是根据pool_name去拿到pool的结构。这里,处理DB中pool_name重名的情况是,返回的是找到的第一个pool。在UI上试了下create操作,并不能创建重名的pool,会报Already exists.的错。看来这个是预防直接写入DB时出现的重名问题。slots_stats里import了TaskInstance,会根据当前task run的情况返回所有pool的状态,上面的UI显示就是调用的这个接口。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
def get_pool(pool_name, session: Session = None):
return session.query(Pool).filter(Pool.pool == pool_name).first()
def get_default_pool(session: Session = None):
return Pool.get_pool(Pool.DEFAULT_POOL_NAME, session=session)
def slots_stats(session: Session = None) -> Dict[str, PoolStats]:
#关键是这几行
#拿到所有的pools
pool_rows: Iterable[Tuple[str, int]] = session.query(Pool.pool, Pool.slots).all()
#初始化返回的PoolStats
for (pool_name, total_slots) in pool_rows:
pools[pool_name] = PoolStats(total=total_slots, running=0, queued=0)
#查询task占用pool的情况,EXECUTION_STATES定义在airflow.ti_deps.dependencies_states,就是running和queued的状态和
'''
EXECUTION_STATES = {
State.RUNNING,
State.QUEUED,
}
'''
state_count_by_pool = (
session.query(TaskInstance.pool, TaskInstance.state, func.count())
.filter(TaskInstance.state.in_(list(EXECUTION_STATES)))
.group_by(TaskInstance.pool, TaskInstance.state)
).all()
#然后就拼成结果返回了
-
class Pool中还有几个方法,是获取不同状态的slots数目。
code比较简单,都是从DB query后根据状态做的filter,贴一个
occupied_slots的实现,其他的都类似。其中running_slots和queued_slots比较好理解,occupied_slots=running_slots+queued_slots,open_slots=Pool.slots-occupied_slots。
1
2
3
4
5
6
7
8
9
10
11
12
def occupied_slots(self, session: Session):
from airflow.models.taskinstance import TaskInstance # Avoid circular import
return (
session
.query(func.sum(TaskInstance.pool_slots))
.filter(TaskInstance.pool == self.pool)
.filter(TaskInstance.state.in_(list(EXECUTION_STATES)))
.scalar()
) or 0
def running_slots(self, session: Session):
def queued_slots(self, session: Session):
def open_slots(self, session: Session):
- 此外,还提供了
to_json方法,以json格式返回Pool的结构。
1
2
3
4
5
6
7
def to_json(self):
return {
'id': self.id,
'pool': self.pool,
'slots': self.slots,
'description': self.description,
}
Usage in Operator
接下来,看下operator是如何传递这个pool的。基本的实现在BaseOperator中,git link: https://github.com/apache/airflow/blob/master/airflow/models/baseoperator.py
看参数定义,除了支持pool指定pool_name,还支持pool_slots,默认值是1,必须大于等于1,表示的是这个task需要占用的slots数目。除了指定这两个值,operator中没有对pool的额外操作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
'''
:param pool: the slot pool this task should run in, slot pools are a
way to limit concurrency for certain tasks
:type pool: str
:param pool_slots: the number of pool slots this task should use (>= 1)
Values less than 1 are not allowed.
:type pool_slots: int
'''
def __init__(
...
pool: Optional[str] = None,
pool_slots: int = 1,
...
):
self.pool = Pool.DEFAULT_POOL_NAME if pool is None else pool
self.pool_slots = pool_slots
if self.pool_slots < 1:
raise AirflowException("pool slots for %s in dag %s cannot be less than 1"
% (self.task_id, dag.dag_id))
Implementation in job scheduler
定义了pool结构,并指定了task用的pool后,再来看下airflow是怎么基于pool进行jobs调度的。实现的code在class SchedulerJob中,git link: https://github.com/apache/airflow/blob/master/airflow/jobs/scheduler_job.py 关键的code已经摘出来了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
def _find_executable_task_instances(self, simple_dag_bag: SimpleDagBag, session=None):
# Get all task instances associated with scheduled
# DagRuns which are not backfilled, in the given states,
# and the dag is not paused
#这个是按一定条件找到可以execute的task_instances,随便看看吧
task_instances_to_examine = (
session
.query(TI)
.filter(TI.dag_id.in_(simple_dag_bag.dag_ids))
.outerjoin(
DR, and_(DR.dag_id == TI.dag_id, DR.execution_date == TI.execution_date)
)
.filter(or_(DR.run_id.is_(None), DR.run_type != DagRunType.BACKFILL_JOB.value))
.outerjoin(DM, DM.dag_id == TI.dag_id)
.filter(or_(DM.dag_id.is_(None), not_(DM.is_paused)))
.filter(TI.state == State.SCHEDULED)
.all()
)
# Get the pool settings
pools = {p.pool: p for p in session.query(models.Pool).all()}
#把task_instances_to_examine放到以pool_name为索引的dict里,结构是pool_name: task_instance list
pool_to_task_instances = defaultdict(list)
for task_instance in task_instances_to_examine:
pool_to_task_instances[task_instance.pool].append(task_instance)
# Go through each pool, and queue up a task for execution if there are
# any open slots in the pool.
# pylint: disable=too-many-nested-blocks
#挨个看pool_to_task_instances里的pool
for pool, task_instances in pool_to_task_instances.items():
pool_name = pool
#意思是如果指定的pool在airflow里没有的话,这个task就不会被执行。但只有一个warnning的log,比较难发现,只能靠写的时候注意了。
if pool not in pools:
self.log.warning(
"Tasks using non-existent pool '%s' will not be scheduled",
pool
)
continue
#找到pool里的open_slots,还记得open_slots的定义不?
open_slots = pools[pool].open_slots(session=session)
num_ready = len(task_instances)
#这是对同一个pool里可执行的task_instances按权重排序,其中priority_weight也可以在operator中指定。排序是基于priority_weight(倒序)和task的执行时间(顺序)。
priority_sorted_task_instances = sorted(
task_instances, key=lambda ti: (-ti.priority_weight, ti.execution_date))
#为排完序的tasks分配slots
for current_index, task_instance in enumerate(priority_sorted_task_instances):
#先检查分配完的情况,就是打log,统计分配的个数等等。。
if open_slots <= 0:
self.log.info(
"Not scheduling since there are %s open slots in pool %s",
open_slots, pool
)
# Can't schedule any more since there are no more open slots.
num_unhandled = len(priority_sorted_task_instances) - current_index
num_starving_tasks += num_unhandled
num_starving_tasks_total += num_unhandled
break
# 要先检查dag level的task concurrency
# Check to make sure that the task concurrency of the DAG hasn't been
# reached.
simple_dag = simple_dag_bag.get_dag(dag_id)
#dag上可以设置task cuncurrency(dag_concurrency_limit),表示这个dag最多能并行跑多少个tasks
current_dag_concurrency = dag_concurrency_map[dag_id]
dag_concurrency_limit = simple_dag_bag.get_dag(dag_id).concurrency
if current_dag_concurrency >= dag_concurrency_limit:
continue
#task上可以设置task cuncurrency(task_concurrency_limit),这是同一个DAG同时在跑多份job的情况下,限制下DAG中指定task的并发。
task_concurrency_limit = simple_dag.get_task_special_arg(
task_instance.task_id,
'task_concurrency')
if task_concurrency_limit is not None:
current_task_concurrency = task_concurrency_map[
(task_instance.dag_id, task_instance.task_id)
]
if current_task_concurrency >= task_concurrency_limit:
continue
#如果task已经跑上了,就不再schedule了(不过不太清楚什么时候会出现这个情况)
if self.executor.has_task(task_instance):
self.log.debug(
"Not handling task %s as the executor reports it is running",
task_instance.key
)
num_tasks_in_executor += 1
continue
#operator里指定的pool_slots,如果大于open_slots,task就继续等着
if task_instance.pool_slots > open_slots:
self.log.info("Not executing %s since it requires %s slots "
"but there are %s open slots in the pool %s.",
task_instance, task_instance.pool_slots, open_slots, pool)
num_starving_tasks += 1
num_starving_tasks_total += 1
# Though we can execute tasks with lower priority if there's enough room
continue
#经过一系列判断,到这一步的task终于进入到running的状态了!!!
executable_tis.append(task_instance)
open_slots -= task_instance.pool_slots
dag_concurrency_map[dag_id] += 1
task_concurrency_map[(task_instance.dag_id, task_instance.task_id)] += 1
看了上面的源码,可以发现除了指定Pool,还可以:
- 通过设置DAG的
task concurrency来限制task并发 - 设置task的
task concurrency来限制DAG并行run情况下的某个task的并发 - 通过
priority_weight影响task调度的优先级 - 以上可以和pool共用
总结
通过Airflow Pool,我们可以很方便的限制tasks的并行度。其实,Airflow还提供了queue的功能,也可以实现类似的功能。而具体queue和pool的区别在哪,需要继续调研。
今天的内容就到这了,如果觉得对你有帮助的话,请关注我的微信号,让我们共同成长进步~

本文作者:Jessychen
版权声明:本博客所有文章除特别声明外,均采用CC-BY-NC-SA 4.0 Int'l许可协议
如需转载,烦请注明出处: