距离上次完成简单的古诗词检索(见 MiniProj之古诗词检索) 也有段时间了。因为需要域名备案的关系,在腾讯云上买了一年的服务器。想着放着也是浪费,前几天就折腾了一把,在上面搭了个简单的api服务,又加了个静态页面。现在已经可以实现在网页上对古诗词进行简单检索了:poem,效果还是不错的。今天,整理一下这其中用到的一些技术。
Mysql
首先,要做成service调用,考虑到性能问题,肯定不能用直接读json文件的方式来做检索了。那么需要一个数据库存储这些诗词数据。这里用了性价比合适的mysql(主要是上手简单)。
初始化
初始化的工作包括mysql安装和用户权限设置。简单起见,mysql直接用了docker里的:
1
2
3
4
5
docker pull mysql:latest
docker run -p 3306:3306 --name mysql -e MYSQL_ROOT_PASSWORD=${password} -d mysql
docker ps #列出容器,可以看到mysql的container
docker exec -it mysql /bin/bash #进入容器
mysql -uroot -p${password} #进入mysql
然后,建立新user,和新DB,以后就用这个user去连数据库了。当然是要牢牢限制user用户的权限滴。完成后记得试一下新用户能不能顺利登陆:
1
2
3
4
mysql> create user "api"@"localhost" identified by "user_password";
mysql> create database api;
mysql> grant select,update,insert,delete on api.* to "api"@"localhost";
mysql> flush privileges;
建库建表
然后,给每种不同类型的诗词建table,以全唐诗和宋词为例,给title和autor都加了索引。同时加了自增索引id字段,这是为了能快速的随机取到结果:
CREATE TABLE `tang` (
`id` int NOT NULL AUTO_INCREMENT,
`author` varchar(16) DEFAULT NULL,
`title` varchar(64) DEFAULT NULL,
`paragraphs` text,
`tags` text,
`uid` varchar(64) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `i_title` (`title`),
KEY `i_author` (`author`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
CREATE TABLE `song` (
`id` int NOT NULL AUTO_INCREMENT,
`author` varchar(16) DEFAULT NULL,
`rhythmic` varchar(64) DEFAULT NULL,
`paragraphs` text,
`tags` text,
PRIMARY KEY (`id`),
KEY `i_rhythmic` (`rhythmic`),
KEY `i_author` (`author`)
) ENGINE=InnoDB AUTO_INCREMENT=21054 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
到此,准备工作就结束了。接下来,需要把json文件里的数据转换成CSV格式,然后导入mysql方便查询。
数据转换
这步,需要写个脚本来做转换,还是用了python来实现。这一步看似简单,但其实python的中文编码是个大坑,折腾了我好久😭。即使到了python3,对中文的支持仍然不尽人意。如果遇到编码报错,只能挨个找方法解决了。并且,注意在用json.dumps的时候加参数ensure_ascii=False,要不然返回的结果就是unicode编码的str了。完整的代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
# -*- coding: utf-8 -*-
'''this script is to convert json to csv for loding into mysql'''
import json,os
import sys
import codecs
sys.stdout = codecs.getwriter("utf-8")(sys.stdout.detach())
def convert():
poem_path_prefix = "./data"
poem_type_list = ["tang", "song", "yuan"]
#poem_type_list = ["tang", "song", "yuan", "shijing"]
for poem_type in poem_type_list:
print("current poem type: %s" % poem_type)
poem_path = "%s/%s" % (poem_path_prefix, poem_type)
fw = open("%s.csv" % poem_path, "w+", encoding="utf-8")
file_list = os.listdir(poem_path)
file_list = [os.path.join(poem_path, f) for f in file_list]
for f in file_list:
if not f.endswith(".json"):
continue
poems = json.load(open(f,"r",encoding='utf-8'))
if poem_type == "tang":
for p in poems:
fw.write("""%s|%s|%s|%s|%s\n""" % (p["author"],p["title"],json.dumps(p['paragraphs'],ensure_ascii=False),json.dumps(p['tags'],ensure_ascii=False) if 'tags' in p else "[]",p['id']))
elif poem_type == "song":
for p in poems:
fw.write("""%s|%s|%s|%s\n""" % (p["author"],p["rhythmic"],json.dumps(p['paragraphs'],ensure_ascii=False),json.dumps(p['tags'],ensure_ascii=False) if 'tags' in p else '[]'))
elif poem_type == "yuan":
for p in poems:
fw.write("""%s|%s|%s\n""" % (p["author"],p["title"],json.dumps(p["paragraphs"],ensure_ascii=False)))
elif poem_type == "shijing":
for p in poems:
fw.write("""%s|%s|%s|%s\n""" % (p["title"],p["chapter"],p["section"],json.dumps(p["content"],ensure_ascii=False)))
if __name__ == '__main__':
convert()
运行后,生成了4个我们需要的data文件。这里,用”|“作为每列的分隔符,是为了保证和文本中原来的字符没有重复。然后,再把它们放到mysql的容器中,入库,以《诗经》为例:
1
2
3
docker cp tang.csv mysql:/data/tang.csv
#enter mysql use root
mysql> load data infile '/data/shijing.csv' ignore into table shijing FIELDS TERMINATED BY '|';
Ohhh,报错了ERROR 1290 (HY000): The MySQL server is running with the --secure-file-priv option so it cannot execute this statement。这是因为在安装MySQL的时候限制了导入与导出的目录权限。只允许在规定的目录下才能导入。只要我们把load文件的存放路径/data目录加入到secure_file_priv就可以了。方法为修改mysql配置文件/etc/mysql/my.conf,加入secure-file-priv= /data这行,然后重启。docker的mysql重启可以直接重启mysql container。操作完成后再试一下,就能load success了。
到这时,我们就成功得到了一个古诗词的数据库了。
Nginx+uwsgi+flask
接下来需要搭建一个api server,接收发来的request,从数据库中检索后返回结果。由于code是python写的,且只需要提供简单的api调用服务,因而选用了轻量的flask框架,搭配nginx+uwsgi来达到目的。这部分的搭建步骤及配置在网上可以很方便的找到,就不多说了。需要注意的是,之前没加nginx测试uwsgi的时候,我用了👇命令是可以正确返回的:
1
curl -i -X post -H "Content-Type: application/json" "http://localhost/poem" -d '{}'
可是在加上nginx后却一直报400 BadRequest的错误。一度认为是nginx配置的问题,但怎么也找不到原因。最后才发现,对nginx来说,指定的method是分大小写的,上面的curl命令中的post需要改为大写的POST才可以。修改后果然就正常了:
1
curl -i -X POST -H "Content-Type: application/json" "http://localhost/poem" -d '{}'
腾讯云API-Gateway
其实完成上面这步,如果自己有域名的话,就可以让前端直接访问对应的api server了。但由于我的域名还在备案,所以这里用了腾讯云的API gateway做了一次转发。API Gateway的使用方法可以见之前的文章API。只要在后端设置中指定”后端域名“为CVM地址,路径为API的路径就可以了。
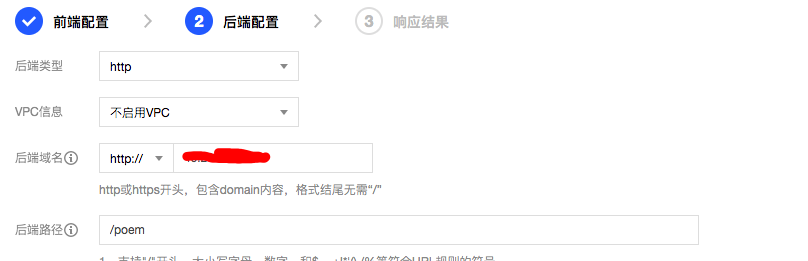
注意:当不开启VPC时,服务地址IP需填写公网IP,若业务服务器安全策略有要求,可仅放通API网关IP的访问(请参考API网关的公网VIP列表)。开启VPC后,请从列表中选择你需要绑定的CLB以及监听器。
所以,最后一步是在nginx的配置中建立IP白名单,只允许腾讯云API网关的IP访问这个接口。
1
2
3
4
5
6
7
8
http {
...
include black.ip;
...
}
#in black.ip
allow xx.xx.xx.xx;
deny all;
所有工作完成后,欣赏一下成果吧:

今天的内容就到这了,如果觉得对你有帮助的话,请关注我的微信号,让我们共同成长进步~

本文作者:Jessychen
版权声明:本博客所有文章除特别声明外,均采用CC-BY-NC-SA 4.0 Int'l许可协议
如需转载,烦请注明出处: